
Southern Newswire Corpus - Historical Wire Articles (1960–1975)
Southern Newswire Corpus - Historical Wire Articles (1960–1975)
Replication, Data, & Models - GitHub Repository. Preliminary Article - arXiv
The Southern Newswire Corpus is a large-scale dataset of historical wire articles from U.S. Southern newspapers, spanning 1960–1975. It covers multiple wire services (AP, UPI, and NEA) and offers both raw OCR and LLM-corrected versions. I developed a open-source pipeline tailored for the digitization of historical newspapers, which allows for performing multiple tasks.
1. Parsing Layout: Articles, headlines, advertisements, and other content regions are identified from raw newspaper page scans. A newly trained layout detection model using Yolo v10 is introduced and available soon at GitHub. Articles which span multiple bounding boxes are combined with a rule-based association which uses bounding-box coordinates to merge them into a single structured observation, preserving the headline, author byline (where identifiable), and article text.


2. Identification of newswire service: I develop three fine-tuned BERT models to identify whether aricles are written by the Associated Press (AP), United Press International (UPI), or Newspaper Enterprise Association (NEA) (Models).


3. Duplication identification: I adopt a noise-robust de-duplication approach (Silcock et al., 2024) to identify replications of the same underlying dispatch, allowing for comparison between local versions of non-local news.
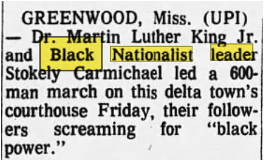
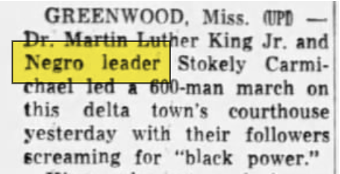
4. LLM-Based Text Correction: I developed a text-correction pipeline that uses Llama3.2, a large language model configured for minimal rewriting. Llama3.2 corrects common OCR artefacts such as misread characters, broken words, or stray punctuation, improving text clarity without introducing anachronistic spellings, while preserving paragraph structure and historical language. Corrections are limited to unambiguous OCR errors, ensuring that archaic or dialect terms remain intact.
Final Dataset: 9.57 million wire articles from 58 million total articles.
Observations: article_id, underlying_wire_id, newspaper_title, date, location, headline, author, newswire_service, raw_article, corrected_article, topic.
🛠️ The American Newspaper Corpus (1960–1975) - Coming Soon
A nationwide historical newspaper article corpus covering >1000 U.S. newspapers from 1960–1975. This dataset offers a comprehensive view of regional newspaper coverage of major events, political shifts, and cultural changes.
Key Features:
- Full Newspaper Archives: Coverage for articles out of copyright.
- Advanced OCR Correction: Fine-tuned large language models for cleaner text.
- Topic and Sentiment Analysis: Track shifts in media discourse.
- Regional Comparisons: Explore variations by county and political alignment.
🚀 Stay tuned for updates as this dataset develops! 😊